


We create awesome templates for you.
Autonomous Character-Scene Interaction Synthesis from Text Instruction
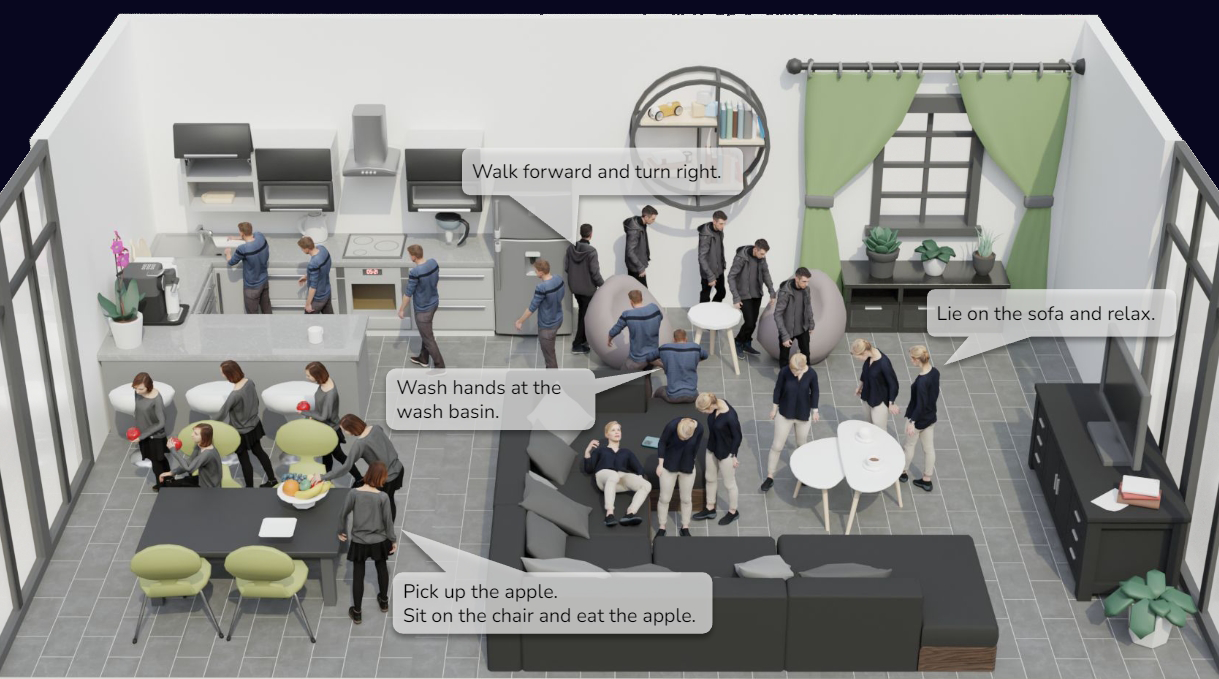
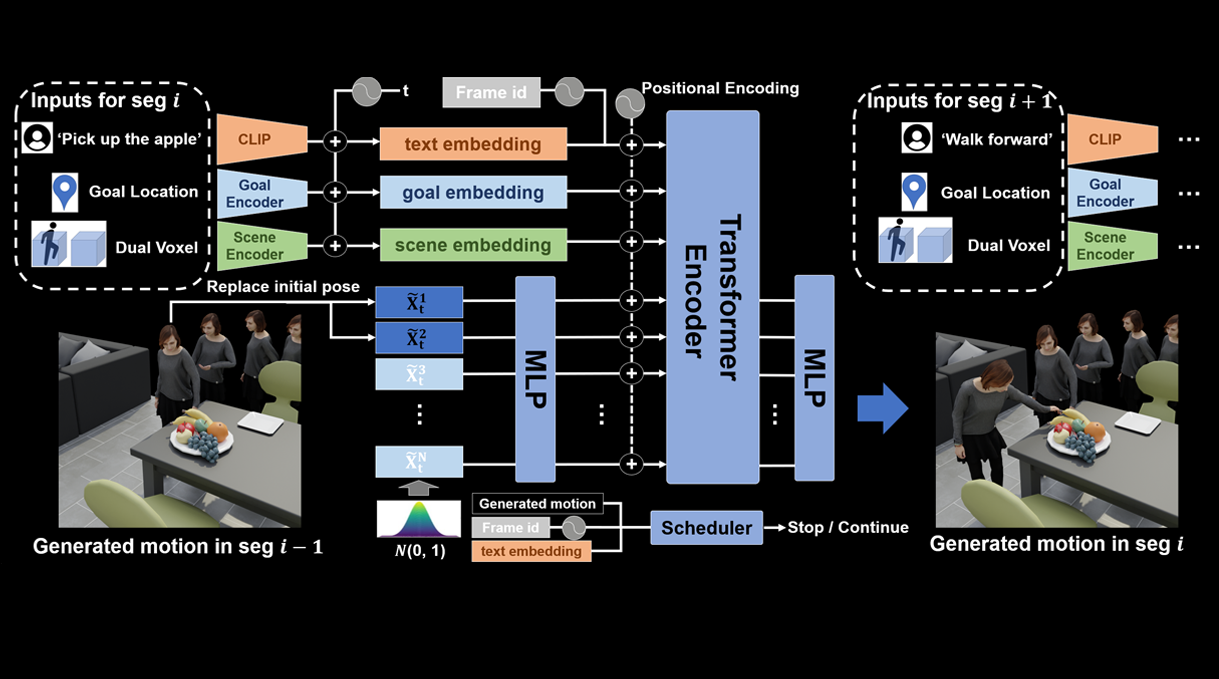
This paper introduces a framework for synthesizing multi-stage scene-aware interaction motions
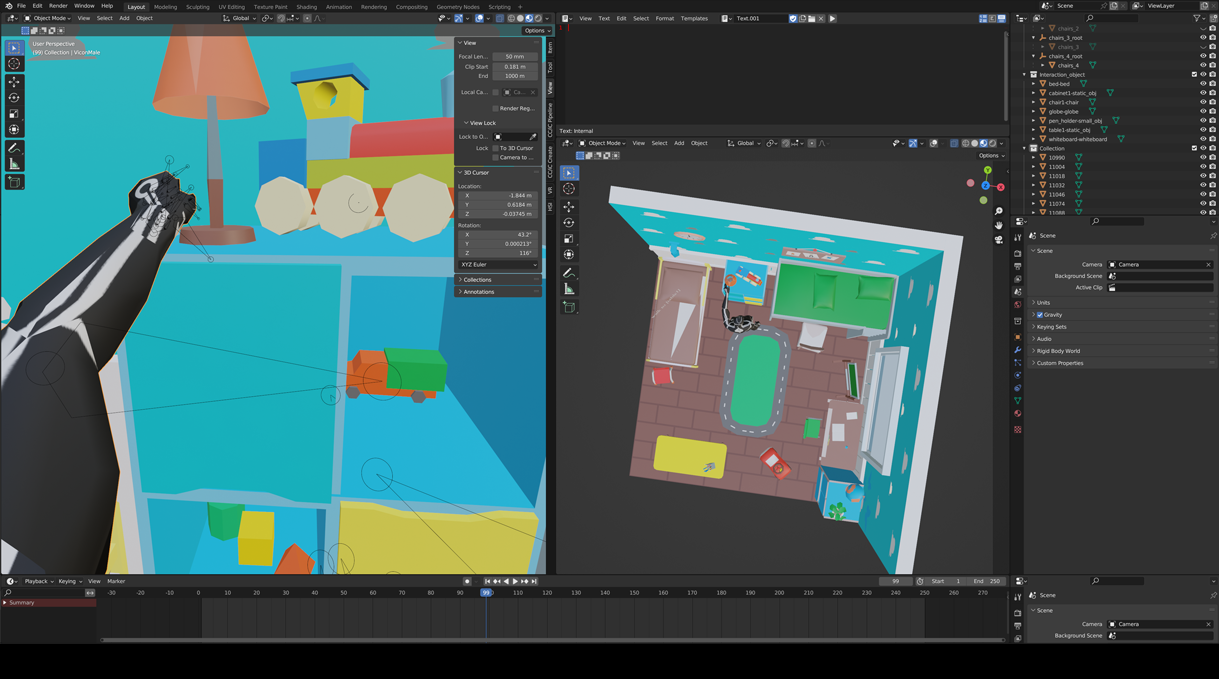
and a comprehensive language-annotated MoCap dataset (LINGO).